| IT |
гуру
16.06.17
✎
11:27
Пытаюсь на NoSQL базе данных (CouchDB) сделать аналог 1С-ных Регистров накопления (остатки и обороты).
К примеру банальная задача остатков товаров на складах и документов движения (приход/расход).
Если сделать остатки через reduce-функцию то проблема что при добавлении/изменении документа движения будет происходить полный пересчет по всем документам.
В 1С это решали например хранением промежуточных итогов на начало каждого месяца и на лету считаем документы с начала нужного месяца чтобы получить итог на требуемую дату.
Вот как бы красиво извратиться на CoudhDB?
Причем чтобы не потерять возможность распараллеливания (и ускорения) вычислений остатков на нодах кластера?
К примеру банальная задача остатков товаров на складах и документов движения (приход/расход).
Если сделать остатки через reduce-функцию то проблема что при добавлении/изменении документа движения будет происходить полный пересчет по всем документам.
В 1С это решали например хранением промежуточных итогов на начало каждого месяца и на лету считаем документы с начала нужного месяца чтобы получить итог на требуемую дату.
Вот как бы красиво извратиться на CoudhDB?
Причем чтобы не потерять возможность распараллеливания (и ускорения) вычислений остатков на нодах кластера?
16.06.17
✎
13:44
(119)
А, понял, ты хочешь чудо-средство, что "я туда только движения пишу, а оно мне вжих, волшебным образом по движениям потом итоги выдавало".
Тогда да, надо будет на десять сервером распаралеливавать, чтобы на-лету остатки считать. Вместо того, чтобы алгоритм хранения продумать, и тогда этой хваленой возможности считать параллельно просто не понадобится, ибо и считать то не надо.
А, понял, ты хочешь чудо-средство, что "я туда только движения пишу, а оно мне вжих, волшебным образом по движениям потом итоги выдавало".
Тогда да, надо будет на десять сервером распаралеливавать, чтобы на-лету остатки считать. Вместо того, чтобы алгоритм хранения продумать, и тогда этой хваленой возможности считать параллельно просто не понадобится, ибо и считать то не надо.
16.06.17
✎
13:49
+(121)
Все думаете, что в NoSql какая-то магия есть. Нет там ничего, обычное хранилище ключ-значение, по-сути откат к старинной Berkley DB, в грамотной маркетинговой обёртке. Вся скорость только за счёт того, что всю базу данных в оперативку засасывает. Ну так можно и sqlite в memory затянуть - там такая скорость будет, закачаешься.
Все думаете, что в NoSql какая-то магия есть. Нет там ничего, обычное хранилище ключ-значение, по-сути откат к старинной Berkley DB, в грамотной маркетинговой обёртке. Вся скорость только за счёт того, что всю базу данных в оперативку засасывает. Ну так можно и sqlite в memory затянуть - там такая скорость будет, закачаешься.
16.06.17
✎
13:54
+(122) *Berkeley DB*
гуру
16.06.17
✎
14:04
(121) (122) Чудо-средство это обычная видяха с GPU ))
Догадайся что будет от распараллеливания?
Догадайся что будет от распараллеливания?
16.06.17
✎
14:49
(124)
Тут должна быть картинка с Джеки Чаном, хватающимся за голову
Затем картинка facepalm.jpg
Насчёт Лаврова - не знаю, может быть, не хочу никого обижать.
Тут должна быть картинка с Джеки Чаном, хватающимся за голову
Затем картинка facepalm.jpg
Насчёт Лаврова - не знаю, может быть, не хочу никого обижать.
гуру
16.06.17
✎
14:57
(125) Глянь ссылки из Ускорение СУБД с помощью GPU и CUDA, сча еще Map-D появилась
http://www.nvidia.ru/object/blog-big-data-gpu-database-ru.html
GPUDB это дело ближайшего будущего, фишка что обычные реляционные плохо работают исключая случаи сложных запросов, много простых смысла нет.
А вот NoSQL это тема на GPU!
http://www.nvidia.ru/object/blog-big-data-gpu-database-ru.html
GPUDB это дело ближайшего будущего, фишка что обычные реляционные плохо работают исключая случаи сложных запросов, много простых смысла нет.
А вот NoSQL это тема на GPU!
гуру
16.06.17
✎
14:58
(120) только коучдб и прочие носкули так не работают, и по этому оперативных остатков там не бывает
гуру
16.06.17
✎
14:58
гуру
16.06.17
✎
14:59
(127) Если сделать очень-очень быстрый "подсчет остатков" то будет казаться что они вполне оперативные.
16.06.17
✎
15:04
(126) в 2013 году. И где они сейчас?
гуру
16.06.17
✎
15:10
(130) Тут https://www.mapd.com/
гуру
16.06.17
✎
15:11
(131) подожди. это реляционка. и без кластера.
16.06.17
✎
15:12
(126)
Это "ускорение ради ускорения".
Тому, у кого в руках молоток, всё вокруг кажется похожим на гвозди. Твое поведение напоминает неофитов, только что узнавших какую-ту хрень, и носящихся с ней, как с писаной торбой, пытаясь приткнуть её где надо и не надо.
Так вот в этой задаче - не надо. Она прекрасно решается простыми и понятными структурами хранения данных, без всякого топового железа и параллельных алгоритмов.
Вместо того, чтобы тупо при фиксации факта посчитать остаток и ЗАПИСАТЬ посчитанное, ты предлагаешь каждый раз загружать на видеокарту весь массив документов и считать всё сначала?
В чём профит? В том, что ты вместо избавляешься от одной лишней записи в момент проведения? Но ради этого придётся городить целый огород с параллельными расчётами, точно также организовывать запись промежуточных итогов для ускорения, да еще и думать, как это всё синхронизировать? На мой взгляд, крайне сомнительная выгода.
Это "ускорение ради ускорения".
Тому, у кого в руках молоток, всё вокруг кажется похожим на гвозди. Твое поведение напоминает неофитов, только что узнавших какую-ту хрень, и носящихся с ней, как с писаной торбой, пытаясь приткнуть её где надо и не надо.
Так вот в этой задаче - не надо. Она прекрасно решается простыми и понятными структурами хранения данных, без всякого топового железа и параллельных алгоритмов.
Вместо того, чтобы тупо при фиксации факта посчитать остаток и ЗАПИСАТЬ посчитанное, ты предлагаешь каждый раз загружать на видеокарту весь массив документов и считать всё сначала?
В чём профит? В том, что ты вместо избавляешься от одной лишней записи в момент проведения? Но ради этого придётся городить целый огород с параллельными расчётами, точно также организовывать запись промежуточных итогов для ускорения, да еще и думать, как это всё синхронизировать? На мой взгляд, крайне сомнительная выгода.
гуру
16.06.17
✎
15:13
(133) после (132) вообще интересно, как автор гуглит...
гуру
16.06.17
✎
15:13
(132) Угу самый идиотизм это пытаться делать виртуальную реляционку и эмуляцию sql на gpu.
Когда там самое то для NoSQL баз, прям просятся.
Когда там самое то для NoSQL баз, прям просятся.
16.06.17
✎
15:14
(127)
Что значит "NoSql так не работают?" Они не разрешают мне хранить в базе то, что я захочу? Зачем они тогда мне?
Что значит "NoSql так не работают?" Они не разрешают мне хранить в базе то, что я захочу? Зачем они тогда мне?
гуру
16.06.17
✎
15:14
господи, да параллельный тэйбл скан там...
гуру
16.06.17
✎
15:14
(134) Блин это просто примеры реальных "реляционных" баз данных "ускоренных" на GPU.
Если на GPU запускать NoSQL базы с MapReduce выигрыш в скорости будет просто офигительный!
Если на GPU запускать NoSQL базы с MapReduce выигрыш в скорости будет просто офигительный!
гуру
16.06.17
✎
15:14
из-за кучи ядер и наличия всего в оперативе получается быстро...
гуру
16.06.17
✎
15:16
(133) >Вместо того, чтобы тупо при фиксации факта посчитать остаток и ЗАПИСАТЬ посчитанное, ты предлагаешь каждый раз загружать на видеокарту весь массив документов и считать всё сначала?
Если внимательно прочитаешь вопрос в (0) то поймешь что как раз хочу этого избежать.
Если внимательно прочитаешь вопрос в (0) то поймешь что как раз хочу этого избежать.
гуру
16.06.17
✎
15:16
вообще стандартные физические sql операторы параллелятся очень хорошо, проблема всегда в блокировках. nosql как раз "избавились от блокировок" путем отказа от оперативности. но и в sql также это есть, версионный режим, когда если запросу не принципиаольно - возвращается предыдущее зафиксированное состояние.
гуру
16.06.17
✎
15:16
nosql - это реально не для бизнеса, это лайки считать.
гуру
16.06.17
✎
15:18
Блин как обычно отклонились от темы и вместо "как это сделать" начинаем "нафига это делать" ))
Короче на данный момент меня не сильно волнует вопрос ускорения на GPU, это дело пока будущего.
Сейчас просто пытаюсь переложить конфу 1С на NoSQL (конкретно CouchDB) БД и все.
Короче на данный момент меня не сильно волнует вопрос ускорения на GPU, это дело пока будущего.
Сейчас просто пытаюсь переложить конфу 1С на NoSQL (конкретно CouchDB) БД и все.
16.06.17
✎
15:19
(138)
Тебе пытаются втолковать, что задача подсчета остатков не требует mapreduce.
(140)
Тогда тоже не вижу плюсов от замены на NoSql. Ты в итоге придешь к такой же структуре хранения данных, что и в реляционной базе, только на самодельных костылях. Закат солнца вручную через key-value pairs получится.
Тебе пытаются втолковать, что задача подсчета остатков не требует mapreduce.
(140)
Тогда тоже не вижу плюсов от замены на NoSql. Ты в итоге придешь к такой же структуре хранения данных, что и в реляционной базе, только на самодельных костылях. Закат солнца вручную через key-value pairs получится.
гуру
16.06.17
✎
15:22
(144) А те кто пытаются это втолковать хотя бы VIEW в классических SQL серверах/бд используют?
Суть не 1С учетных систем тех же SAP'ов и прочих OEBS/Axapta как раз в полноценном использовании возможностей SQL сервера.
Я же просто пытаюсь использовать полноценно возможности NoSQL сервера.
Суть не 1С учетных систем тех же SAP'ов и прочих OEBS/Axapta как раз в полноценном использовании возможностей SQL сервера.
Я же просто пытаюсь использовать полноценно возможности NoSQL сервера.
гуру
16.06.17
✎
15:23
(144) Плюсы есть, и в принципе проблема уже решена еще на 1-й странице и без всяческих "тех же структур".
16.06.17
✎
15:24
Вообще, обычно обсуждение NoSql идёт по одному сценарию:
- Йоу, смотрите как быстро я в неё документ пишу и извлекаю!
- А выберите ка мне всех клиентов, купивших одеколон за месяц на сумму более 10 тыр.
- Ээээ, а зато тут можно всё параллельно
- Йоу, смотрите как быстро я в неё документ пишу и извлекаю!
- А выберите ка мне всех клиентов, купивших одеколон за месяц на сумму более 10 тыр.
- Ээээ, а зато тут можно всё параллельно
гуру
16.06.17
✎
15:25
(147) Скажи вот у тебя 100 пользователей одновременно запустили отчет который "выберите ка мне всех клиентов, купивших одеколон за месяц на сумму более 10 тыр. "
Что будет? И что будет в NoSQL ?
Что будет? И что будет в NoSQL ?
гуру
16.06.17
✎
15:28
И да я совсем не против обычного SQL, совсем не собираюсь от него отказываться и не призываю это делать других.
Суть применять NoSQL в тех задачах где он лучше работает.
Не выйдет чисто на CouchDB ну заюзаю Posgtres для актуальных остатков, где будут чисто ссылки-гуиды на доки, а сами доки буду в NoSQL хранить.
Суть применять NoSQL в тех задачах где он лучше работает.
Не выйдет чисто на CouchDB ну заюзаю Posgtres для актуальных остатков, где будут чисто ссылки-гуиды на доки, а сами доки буду в NoSQL хранить.
гуру
16.06.17
✎
15:29
(149) *Postgres
16.06.17
✎
15:31
(148)
Для начала окажется, что клиент не входит в ключ по документам. Потом окажется что вообще, клиент записывается просто строкой в данных документа. И т.д и т.п. Короче, решить можно, но надо неделю на программирование и десять серверов в параллель. Только и всего.
Если ты будешь говорить, что у тебя и документы по клиенту индексированы, и они отдельной сущностью сделаны, с включением в документ только ссылки - то чем это в итоге отличается от SQL баз?
SQL базы - это по сути надстройка над key-value хранилищами, и всё, что можно сделать на NoSql - точно так же можно сделать и в реляционной базе.
Для начала окажется, что клиент не входит в ключ по документам. Потом окажется что вообще, клиент записывается просто строкой в данных документа. И т.д и т.п. Короче, решить можно, но надо неделю на программирование и десять серверов в параллель. Только и всего.
Если ты будешь говорить, что у тебя и документы по клиенту индексированы, и они отдельной сущностью сделаны, с включением в документ только ссылки - то чем это в итоге отличается от SQL баз?
SQL базы - это по сути надстройка над key-value хранилищами, и всё, что можно сделать на NoSql - точно так же можно сделать и в реляционной базе.
гуру
16.06.17
✎
15:33
(151) Документы да отдельная сущность, вот их содержимое нет, внутри.
16.06.17
✎
15:36
(152)
То есть чтобы отобрать все доки по конкретному клиенту нужно все доки перебрать?
То есть чтобы отобрать все доки по конкретному клиенту нужно все доки перебрать?
гуру
16.06.17
✎
15:37
(153) параллельно!!!111одиодин в кластере!!!одинодин
гуру
16.06.17
✎
15:38
(153) Не нужно, они уже все заранее отобраны и сложены во view.
(154) Очень смешно...
(154) Очень смешно...
гуру
16.06.17
✎
15:40
Прикольно когда обсирают осуждают нечто слыша об этом по верхам ))
16.06.17
✎
15:42
(0) я тут маленькую базку писал, с sqlite уткнулся в транзакции параллельно записать не получается. Открыто соединение должно быть только в 1 месте и если идет команда sql происходит блокировка.
Короче перевел на MS SQL LocalDB
Зачем велосипед изобретать..
NoSQL только для хранения документов,картотек, не для вычислений и тем более уж параллельных.
Короче перевел на MS SQL LocalDB
Зачем велосипед изобретать..
NoSQL только для хранения документов,картотек, не для вычислений и тем более уж параллельных.
гуру
16.06.17
✎
15:42
(155) да понятно, что по факту создается еще одна табличка по типу олапа, в которую демоны складывают периодически данные. эта периодичность в общем случае непрогнозируема. место, занимаемое данными - растет прямо пропорционально основным табличкам и в геометрической прогрессии по количеству разрезов информации.
гуру
16.06.17
✎
15:46
(158) Угадал, но "код демона" пишется на том же языке что и и сама система ))
16.06.17
✎
15:48
(159)
Это я как-раз и называю - "закат солнца вручную на костылях вокруг key-value pairs".
Это я как-раз и называю - "закат солнца вручную на костылях вокруг key-value pairs".
гуру
16.06.17
✎
15:49
(160) Главную фишку знаешь? "Программисту" не обязательно будет нуна учить SQL ))
16.06.17
✎
15:53
(161) не уж то это так сложно?
16.06.17
✎
15:54
(162) не ужто какой нибудь LINQ проще чем селект на обычном SQL?
16.06.17
✎
15:55
(157)
В sqlite в один момент может писать только один писатель, блокируется вся база. Хотя, если для записи использовать только один процесс, которому другие шлют запросы на запись, и включить WAL - он пишет с охренительной скоростью. На своей машинке Corei5 3.2GHz с SATA винтом делал тест - начать транзакцию, записать десять строк в таблицу с тремя полями, зафиксировать транзакцию - в среднем 70000 транзакций в секунду. Периодически, когда скидывало кэш на диск, падало до 3000 транзакций в секунду.
При этом в WAL режиме записывающие не мешают читающим нисколько, то есть запросы других клиентов на чтение выполнялись во время транзакций записи.
В sqlite в один момент может писать только один писатель, блокируется вся база. Хотя, если для записи использовать только один процесс, которому другие шлют запросы на запись, и включить WAL - он пишет с охренительной скоростью. На своей машинке Corei5 3.2GHz с SATA винтом делал тест - начать транзакцию, записать десять строк в таблицу с тремя полями, зафиксировать транзакцию - в среднем 70000 транзакций в секунду. Периодически, когда скидывало кэш на диск, падало до 3000 транзакций в секунду.
При этом в WAL режиме записывающие не мешают читающим нисколько, то есть запросы других клиентов на чтение выполнялись во время транзакций записи.
гуру
16.06.17
✎
15:57

гуру
16.06.17
✎
15:58

гуру
16.06.17
✎
15:58
(162) (163) Никаких LINQ'ов обычный JavaScript код.
гуру
16.06.17
✎
15:59

гуру
16.06.17
✎
16:00

гуру
16.06.17
✎
16:01
ну и к вопросу о сложности...
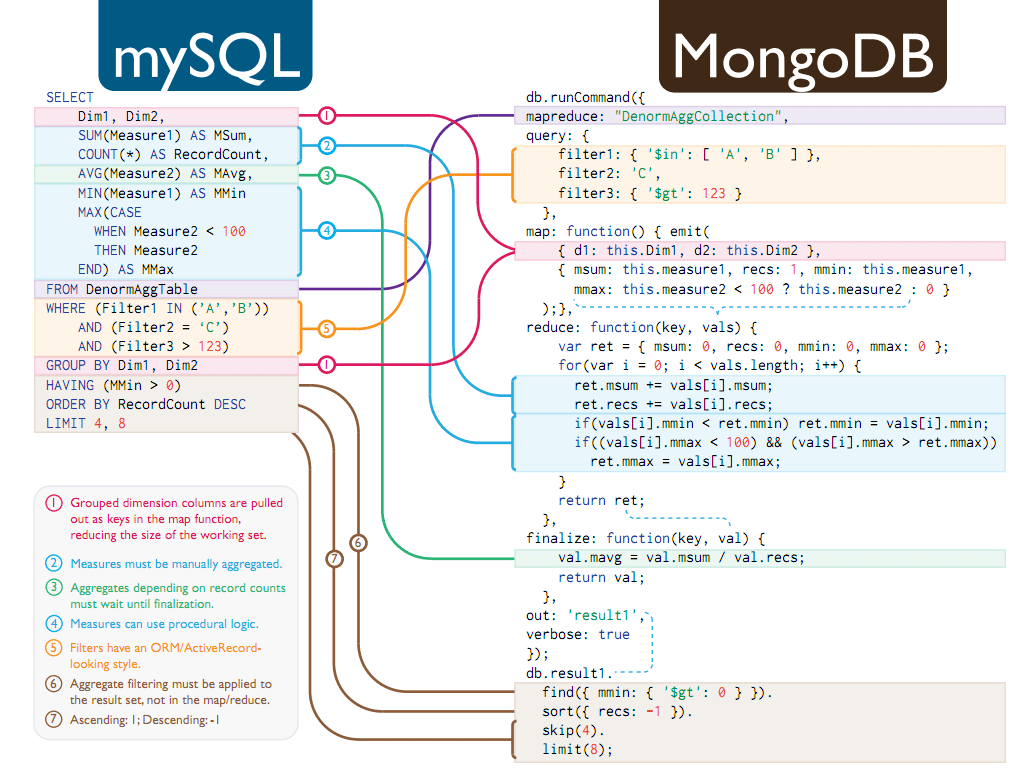
гуру
16.06.17
✎
16:01
(165) Блин я им про фому а они мне про ерёму...
Не считайте меня дурным и не знающим про "индексы".
Никакой "индекс" не поможет когда у вас данные новые колбасят и тут же хотят видеть остатки, пускай и не совсем актуальные но быстро-быстро, еще быстрее...
И если тыщщи юзеров в одной базе.
Не считайте меня дурным и не знающим про "индексы".
Никакой "индекс" не поможет когда у вас данные новые колбасят и тут же хотят видеть остатки, пускай и не совсем актуальные но быстро-быстро, еще быстрее...
И если тыщщи юзеров в одной базе.
гуру
16.06.17
✎
16:05
(170) (170) Эээ к вопросу о сложности а кто понял что справа вообще то много независимых штук?
1. есть функция MAP
2. есть функция REDUCE которая работает по результатам MAP но ей глубоко пофиг что там внутри, лишь бы структуру получить верную по полям
3. есть финализе которому тоже пофиг что там ранее
4. ну и фильтр на входе который можно менять не трогая функции!
1. есть функция MAP
2. есть функция REDUCE которая работает по результатам MAP но ей глубоко пофиг что там внутри, лишь бы структуру получить верную по полям
3. есть финализе которому тоже пофиг что там ранее
4. ну и фильтр на входе который можно менять не трогая функции!
гуру
16.06.17
✎
16:06
(172)+ Короче любую часть можно независимо переписать (это разные модули и они выполняются независимо и даже на разных нодах) и оно будет работать!!!
А терь попробуйте исправить запросик SQL...
А терь попробуйте исправить запросик SQL...
16.06.17
✎
16:08
(173) У тебя js головного мозга. Как у одного товарища с .net
гуру
16.06.17
✎
16:11
(174) Инструмент/технологию товарища с .Net вполне успешно использую. А вы?
16.06.17
✎
16:12
(175) А нам-то зачем?
гуру
16.06.17
✎
16:12
(173) по факту, то же самое можно сделать и со скулем в виде
mysql.query("select dim1,dim2").then((queryresult)=>{ result = queryresult.filter(/*тут то, что в where*/).map(/* тут преобразования полей из select*/).reduce(/* тут аггрегация*/).filter(/*тут фильтр having*/); return resolve(result)});
и никакой большой заслуги именно nosql движка тут нет. при этом map и filter параллелятся и так. reduce по сути своей однопоточен, так что преимуществ никаких у nosql нет
mysql.query("select dim1,dim2").then((queryresult)=>{ result = queryresult.filter(/*тут то, что в where*/).map(/* тут преобразования полей из select*/).reduce(/* тут аггрегация*/).filter(/*тут фильтр having*/); return resolve(result)});
и никакой большой заслуги именно nosql движка тут нет. при этом map и filter параллелятся и так. reduce по сути своей однопоточен, так что преимуществ никаких у nosql нет
гуру
16.06.17
✎
16:15
не, когда я изучал js и дошел там до методов массива - я в очередной раз пожалел, что в 1с нет лямбд, да. но наличие map/reduce никак нельзя признавать "киллер фичей"
16.06.17
✎
16:16
(157)
sqlite - это кстати не NoSql. Это самая натуральная встраиваемая реляционная БД.
sqlite - это кстати не NoSql. Это самая натуральная встраиваемая реляционная БД.
гуру
16.06.17
✎
16:18
тем более, что далеко не факт, что map и reduce функции исполняются сервером субд, а не клиентским приложением ;)
гуру
16.06.17
✎
16:19
(176) Действительно "а зачем?"
(177) У CouchDB из коробки отказоустойчивость кластера.
Попробуй на SQL взять допустим 10 компов (без выделенного главного/сервера) и на них поднять шустро работающую учетную систему.
Которая продолжает работать пока хотя бы один комп включен и ускоряет работу когда они назад включаются/добавляются.
(177) У CouchDB из коробки отказоустойчивость кластера.
Попробуй на SQL взять допустим 10 компов (без выделенного главного/сервера) и на них поднять шустро работающую учетную систему.
Которая продолжает работать пока хотя бы один комп включен и ускоряет работу когда они назад включаются/добавляются.
гуру
16.06.17
✎
16:21
(181)+ Суть что то что 1С получается путем написания сервера 1С с разворачиванием кластера и т.д. тут все работает из коробки на "бесплатных" технологиях.
Короче для неких ниш решение вполне оптимальное и наилучшее. Представьте кассы которые без сервера шустро-шустро пашут без тормозов.
Короче для неких ниш решение вполне оптимальное и наилучшее. Представьте кассы которые без сервера шустро-шустро пашут без тормозов.
16.06.17
✎
16:21
(181) Вот.
гуру
16.06.17
✎
16:22
(183) "Вам" не зачем )) Зачем мне это моя дело )))
16.06.17
✎
16:24
(181)
Даже не знаю, как еще объяснить. Ты пытаешься оправдать вещь возможностью самой вещи, не пытаясь подумать, а ценна ли эта возможность сама по себе?
Что например, если сделать традиционную бд с грамотно организованным хранилищем, то сама необходимость в кластере из десяти серверов отпадёт?
Ты же не знаешь, как внутри их кластер реализован?
Поэтому, допустим, чем он отличается от десятка серверов с MS-SQL с настроенной авто-репликацией - не сможешь объяснить?
Даже не знаю, как еще объяснить. Ты пытаешься оправдать вещь возможностью самой вещи, не пытаясь подумать, а ценна ли эта возможность сама по себе?
Что например, если сделать традиционную бд с грамотно организованным хранилищем, то сама необходимость в кластере из десяти серверов отпадёт?
Ты же не знаешь, как внутри их кластер реализован?
Поэтому, допустим, чем он отличается от десятка серверов с MS-SQL с настроенной авто-репликацией - не сможешь объяснить?
16.06.17
✎
16:26
(182)
У меня на работе кассы шустро-шустро пашут без тормозов.
Без NoSql и кластеров. На sqlite :)
У меня на работе кассы шустро-шустро пашут без тормозов.
Без NoSql и кластеров. На sqlite :)
гуру
16.06.17
✎
16:32
(186) И скажи если взять сначала пробить на всех кассах а потом через пару минут все кроме одной вырубить, одна оставшаяся будет сообщать о продажах всех остальных?
Тут это "из коробки".
Тут это "из коробки".
гуру
16.06.17
✎
16:32
(187)+ Отдельного сервера кроме касс нету
16.06.17
✎
16:35
(187) Ты хочешь базу между клиентами распределять?
16.06.17
✎
16:36
Ты немного не понимаешь требования к кассам. Она не должна отчитываться за других. Она должна человеку чек пробить, даже если сеть пропала. А когда сеть есть, скинуть продажу в учётную систему. Или у тебя это магия и при отсутствии сети работает? Через астрал?
гуру
16.06.17
✎
16:36
(187) ну потеряются часть транзакций, да и буй с ним, да...
16.06.17
✎
16:37
"оставшаяся будет сообщать о продажах" - в этом месте предвидится затык
16.06.17
✎
16:38
(189)
Ага. Всю базу всех продаж реплицировать на каждую кассу. Понял, да. На каждой кассе поставим Xeon + 128Gb RAM + 1TB винт :)
Ага. Всю базу всех продаж реплицировать на каждую кассу. Понял, да. На каждой кассе поставим Xeon + 128Gb RAM + 1TB винт :)
гуру
16.06.17
✎
16:41
"В качестве домашнего задания можете провести такой эксперимент. Уроните одну ноду. Убедитесь, что документ можно обновить, используя только оставшиеся две ноды. Затем поднимите упавшую ноду и быстро-быстро запросите с нее документ. Убедитесь, что никакого конфликта не происходит и вы получаете последнюю ревизию."
http://eax.me/couchdb/
Это если кто по английски не может
http://eax.me/couchdb/
Это если кто по английски не может
16.06.17
✎
16:41
+(193)
А, еще крутой GPU нужен, обязательно. Будет остатки в паралель считать. А когда затишье, кассир в думчик поиграет :)
А, еще крутой GPU нужен, обязательно. Будет остатки в паралель считать. А когда затишье, кассир в думчик поиграет :)
гуру
16.06.17
✎
16:43
(193) 4 а лучше 16 Gb RAM хватит за глаза
https://developer.couchbase.com/documentation/server/current/install/pre-install.html
https://developer.couchbase.com/documentation/server/current/install/pre-install.html
16.06.17
✎
16:43
(194) Это всё хорошо. Ноды у тебя где будут?
гуру
16.06.17
✎
16:46
(197) на планшетах/мобильных кассах
гуру
16.06.17
✎
16:46
(194) для одного документа и локальной сети - предполагаю, что время синхронизации пренебрежимо мало.
а теперь представь ситуацию нарушения связности между нодами вместо падения, с одновременным исправлением одних данных в двух нодах. или когда канал между нодами - не 1гбит сеть, да и данных с сотню мегабайт накопилось
а теперь представь ситуацию нарушения связности между нодами вместо падения, с одновременным исправлением одних данных в двух нодах. или когда канал между нодами - не 1гбит сеть, да и данных с сотню мегабайт накопилось
гуру
16.06.17
✎
16:46
(198)+ и еще на ТСД по складу бегать... и стоять на десктопах менагеров
16.06.17
✎
16:47
(196) На каждую кассу по 16 гиг?
гуру
16.06.17
✎
16:47
сферические примеры кластеров в вакууме часто разбиваются о реальность каналов связи
16.06.17
✎
16:48
И на ТСД держать реплику все базы????
гуру
16.06.17
✎
16:48
(199) Сетка не локалка между нодами даже не рассматриваю пока, при плохих каналах согласен что синхронизация будет очень долгой.
Блин мне нужна некая технология, я ее нашел и пытаюсь заюзать как нуна. Так как 1С без плясок с бубнами и разного программного шаманства не позволяет.
Блин мне нужна некая технология, я ее нашел и пытаюсь заюзать как нуна. Так как 1С без плясок с бубнами и разного программного шаманства не позволяет.
гуру
16.06.17
✎
16:49
(203) Шутки сча понимать надо, в будущем это будет не шутка
гуру
16.06.17
✎
16:49
(204) получение оперативных данных - это не "как нуна"
гуру
16.06.17
✎
16:50
(206) Если мы знаем что "вот эти данные не оперативные" то легко можем подождать или сделать спецзапрос оперативных.
16.06.17
✎
16:50
(204) Ну чтож дерзай, как сделаешь расскажешь
гуру
16.06.17
✎
16:51
У меня такое подозрение что адепты FTP спорят с любителем торрентов...
16.06.17
✎
16:51
В теме слишком мало блокчейнов...
гуру
16.06.17
✎
16:52
(210) ты сделал мой день!
16.06.17
✎
16:52
(209) Только вот по фтп каждый берет ровно свой файлик в 100к, а через торренты вся база мигрирует в 100г
гуру
16.06.17
✎
16:53
(210) (211) шшш тут нельзя про это...
гуру
16.06.17
✎
16:53
(207) а как ты поймешь, что данные не оперативные при нарушении связности?
гуру
16.06.17
✎
16:53
(212) Странно... почему я через торренты беру (и раздаю) только тот файлик хоть пару байт (на самом деле захватываю и соседние ибо блоки) а?
гуру
16.06.17
✎
16:59
(215) да нет, при запросе select from where ты получишь только нужные тебе данные, при репликации - ты вынужден получить все + постоянно отслеживать изменения. это на самом деле большая проблема. например при попытке изменить одновременно документ в двух местах, когда тебе пофиг, все хорошо, а вот "объект уже захвачен для редактирования" когда не пофиг, уже не получится.
гуру
16.06.17
✎
17:05
(214) Там немного интереснее и проще есть встроенный механизма разрешения конфликтов с сохранением конфликтующих копий
http://guide.couchdb.org/draft/conflicts.html
http://guide.couchdb.org/draft/conflicts.html
гуру
16.06.17
✎
17:12
(217)+ И да нарушение связности так же легко определяется и можно это вручную отработать уже.
Но блин это полезли в моменты которые пока даже не думал, мне бы пока просто падение 1-2 серверов исключить.
Кстати! Там же через http прокси обращение к CouchDB работает, короче что кластер развалится на несколько "работающих" групп нод маловероятно.
Суть что да можно настроить напрямую на ноды связь, а можно через прокси который нагрузку между нодами разруливает
Но блин это полезли в моменты которые пока даже не думал, мне бы пока просто падение 1-2 серверов исключить.
Кстати! Там же через http прокси обращение к CouchDB работает, короче что кластер развалится на несколько "работающих" групп нод маловероятно.
Суть что да можно настроить напрямую на ноды связь, а можно через прокси который нагрузку между нодами разруливает
гуру
16.06.17
✎
17:19
(218) ну так тогда нафиг этот "кластер", если прокся упадет?
гуру
16.06.17
✎
17:22
(219) проксю легко и на лету поменять же прямо из клиента