| 1C |
ptiz, Дмитрий, Доминошник, timurhv, Ёпрст, trk415e76, Eiffil123, Redaktor, H A D G E H O G s, Silgis, Rovan, AutoAns, okmail, Ногаминебить, Asmody, Anton1307, d4rkmesa, Многолетний Апельсин, Garykom, Злоп, Калиостро, Михаил Козлов, mikecool, DimR_71, SleepyHead, MWWRuza, vis, Шурик71, dchumak, Волшебник, maxab72, denk32, Inga_groza, dmt, zenik, zva, Timon1405, Gucci76, akronim, Vstur, Джордж1, Dzenn, Лодырь, lends
☑
22.01.25
✎
15:26
Коллеги, привет.
Такая задачка — у нас есть массив из 100 000 000 кодов "Честного знака" — они все уникальны. Понятно, что делать индекс по уникальным значениям нельзя.
Все коды загружены в регистр сведений. Нужно обеспечить средствами 1С более эффективный поиск по таблице, нежели простым перебором.
Идея для решения задачки такая — придумать алгоритм, на входе которого будет уникальный код честного знака, а на выходе — неуникальное число от 1 до 1000, причём вероятность получения любого числа от 1 до 1000 в случае уникальности кодов (отбрасывая левые нули) должна быть примерно равной. Для этого числа можно создать дополнительную колонку регистра и по ней индексировать.
Знаете ли вы готовые алгоритмы для решения подобной задачи?
Такая задачка — у нас есть массив из 100 000 000 кодов "Честного знака" — они все уникальны. Понятно, что делать индекс по уникальным значениям нельзя.
Все коды загружены в регистр сведений. Нужно обеспечить средствами 1С более эффективный поиск по таблице, нежели простым перебором.
Идея для решения задачки такая — придумать алгоритм, на входе которого будет уникальный код честного знака, а на выходе — неуникальное число от 1 до 1000, причём вероятность получения любого числа от 1 до 1000 в случае уникальности кодов (отбрасывая левые нули) должна быть примерно равной. Для этого числа можно создать дополнительную колонку регистра и по ней индексировать.
Знаете ли вы готовые алгоритмы для решения подобной задачи?
22.01.25
✎
15:29
хотя блин я кажется уже сам догадался... сначала сделать хэширование, потом просуммировать все коды символов хеширования и взять остаток от деления на 1000
22.01.25
✎
15:30
"Понятно, что делать индекс по уникальным значениям нельзя."
Нет, непонятно.
Нет, непонятно.
22.01.25
✎
15:31
Возможно вы индекс не хотите делать по причине его размера, других объяснений нежелания у меня нет.
22.01.25
✎
15:32
(3) ну конечно
22.01.25
✎
15:33
(4) Поиск в 100000 строк тоже глупо
22.01.25
✎
15:34
(5) влезать с оценочными суждениями, но без решений — примерно раз в 500 глупее
22.01.25
✎
15:35
Я просто приколочу это здесь
p.s. Автор не понимает размера работ
p.s. Автор не понимает размера работ
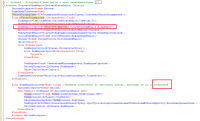
|
22.01.25
✎
15:35
(1) осталось доказать, что вероятность равномерная
22.01.25
✎
15:35
(6) Вам хорошего дня.
22.01.25
✎
15:37
(1) А куда потом вкрячить это поле? Речь вообще про 1С?
ИМХО, лучше пересмотреть задачу целиком.
ИМХО, лучше пересмотреть задачу целиком.
22.01.25
✎
15:40
а... вижу
"дополнительную колонку регистра" - а смысл?
Если новое поле сделать индексированным - в этот индекс 1С также включит все измерения РС, и индекс будет "большим".
Шаманить в СУБД напрямую?
"дополнительную колонку регистра" - а смысл?
Если новое поле сделать индексированным - в этот индекс 1С также включит все измерения РС, и индекс будет "большим".
Шаманить в СУБД напрямую?
22.01.25
✎
15:44
(грустно смотрю на свой справочник из 965 000 000 кодов)
22.01.25
✎
15:45
Вот тоже с Ежиком согласен.
Мне тоже совсем не понятно, с какой стати не нужен индекс по уникальным значениям?
Может вы тогда пометку удаления еще предложите индексирвоать?
Мне тоже совсем не понятно, с какой стати не нужен индекс по уникальным значениям?
Может вы тогда пометку удаления еще предложите индексирвоать?
22.01.25
✎
15:48
(12) Завод?
22.01.25
✎
15:51
(12) у нас скормнее, 198 577 055..но, это не чз, просто марка
22.01.25
✎
15:52
ЧЗ -это вроде 31 цифра
22.01.25
✎
15:59
(0) Зачем искать по всей таблице из 100М записей, наверняка коды в регистре хранятся с привязкой к номенклатуре.
22.01.25
✎
16:09
(14) Хуже - лекарства оптом.
22.01.25
✎
16:50
(17) При наличии индексов в 100М таблице - любая запись найдется за максимум 30 шагов чтения строк таблицы.
22.01.25
✎
17:05
(0) >Знаете ли вы готовые алгоритмы для решения подобной задачи?
Знаю.
Не хранить коды в 1С.
Вынести их наружу.
Знаю.
Не хранить коды в 1С.
Вынести их наружу.
22.01.25
✎
17:10
(20)+ В 1С хранить только SGTIN или SSCC, их же указывать в доках
Нахрена вам в базе 1С криптохвосты?
Нахрена вам в базе 1С криптохвосты?
22.01.25
✎
17:11
(21)+ а индекс по SGTIN уже есть
Это GTIN часть
Это GTIN часть
22.01.25
✎
17:40
(18) Вам кстати криптохвосты низзя вроде хранить в базе по закону. В отличие от других.
22.01.25
✎
18:26
(23) Нет такого
22.01.25
✎
18:27
(23) У нас их и нет, только sgtin. Кстати, в (0) тоже не указано - какой именно код они хранят.
22.01.25
✎
18:56
(0) >> Понятно, что делать индекс по уникальным значениям нельзя.
Вы там совсем ёбнулись что ли?
Вы там совсем ёбнулись что ли?
22.01.25
✎
19:05
На уровне бреда: а если запихнуть коды во внешнюю базу, не 1С, и ходить в неё через внешний источник, быстрее не получится?
22.01.25
✎
19:11
А может всё-таки бахнем индекс? Право, сударь! Для быстрого поиска люди придумали ИНДЕКСЫ!

|
22.01.25
✎
19:13
(19) 👍
22.01.25
✎
19:48
(24)
"IV. Правила хранения и использования кодов маркировки 4.1. Код маркировки (далее – КМ), включающие в себя идентификатор ключа подписи и код проверки (крипто-часть КМ) могут храниться в учетной системе или АСУТП Участника только в процессе производственного цикла. После отправки отчета об использовании (нанесении) КМ крипто-часть должна быть удалена. Хранение КМ, включающих в себя крипто-часть, после их нанесения на готовую продукцию и отправки отчета об использовании кодов маркировки в учетной системе или АСУТП Участника запрещено."
"IV. Правила хранения и использования кодов маркировки 4.1. Код маркировки (далее – КМ), включающие в себя идентификатор ключа подписи и код проверки (крипто-часть КМ) могут храниться в учетной системе или АСУТП Участника только в процессе производственного цикла. После отправки отчета об использовании (нанесении) КМ крипто-часть должна быть удалена. Хранение КМ, включающих в себя крипто-часть, после их нанесения на готовую продукцию и отправки отчета об использовании кодов маркировки в учетной системе или АСУТП Участника запрещено."
23.01.25
✎
12:29
(8) угу, распределение оказалось неравномерным ) но при остатке от деления на 100 — вполне себе вышло, стандартное отклонение — 28,5229 :-)
23.01.25
✎
12:31
(29) нет, ну можно конечно, просто индексная таблица будет невероятно большой, и при добавлении новых значений она будет сильно кряхтеть
23.01.25
✎
12:31
(34) Не жмотитесь. При наличии 100 млн марок должны быть деньги на систему хранения типа SAS
24.01.25
✎
10:11
(35) ста миллионов не будет, будет в районе миллиона, задачу специально означил таким образом, чтобы абстрагировать её в сторону алгоритма
24.01.25
✎
10:45
1. перевести код марки в огромное число N
2. получить его квадрат K = N*N
3. взять случайные 3 цифры из квадрата числа K (рядом подряд или произвольно, запомнить позиции и всегда брать их или из середины числа без 0 слева)
4. получится 0..999 - если надо от 1 до 1000 сделать +1
2. получить его квадрат K = N*N
3. взять случайные 3 цифры из квадрата числа K (рядом подряд или произвольно, запомнить позиции и всегда брать их или из середины числа без 0 слева)
4. получится 0..999 - если надо от 1 до 1000 сделать +1
24.01.25
✎
10:40
(37) а чего тогда просто не взять 3 случайных цифры?
24.01.25
✎
10:42
(38) GTIN в начале, случайного распределения не будет
они вероятно чаще с одними и теми же поставщиками работают
они вероятно чаще с одними и теми же поставщиками работают
24.01.25
✎
10:44
(38) но правильно заметил от "случайные" надо избавиться для хеша, для повторяемости
или всегда в середине брать
или запомнить случайные позиции и всегда брать их
или всегда в середине брать
или запомнить случайные позиции и всегда брать их
24.01.25
✎
10:50
бери 3 последние цифры числа π, не ошибешься
24.01.25
✎
10:54
(41) тоже неплохая идея если брать "3 последние цифры числа π" начиная с позиции "перевести код марки в огромное число N"
24.01.25
✎
13:03
(42) Изобретаем свой хэш?